作者:原创

自1月20日,DeepSeek-R1发布并同步开源模型权重以来,舆论不断发酵,越来越多的人注意到了这个国产大模型的强大。
DeepSeek-R1在数学、代码、自然语言推理等任务上,性能比肩OpenAI o1正式版。

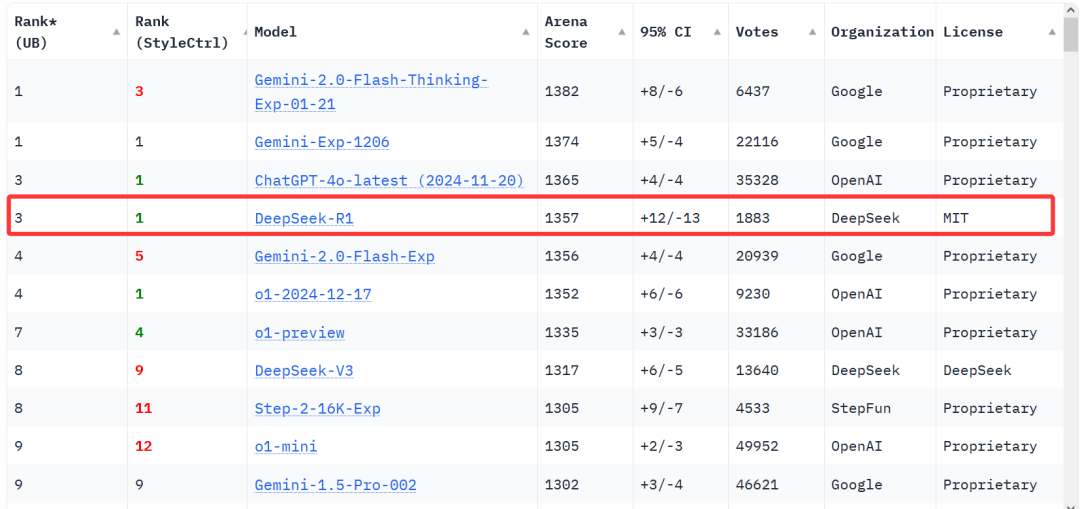
1月24日,在专业大模型排名 Arena 上,DeepSeek-R1 基准测试已经升至全类别大模型第三,其中在风格控制类模型(StyleCtrl)分类中与 OpenAI o1 并列第一。而其竞技场得分达到1357分,略超OpenAI o1的1352分。
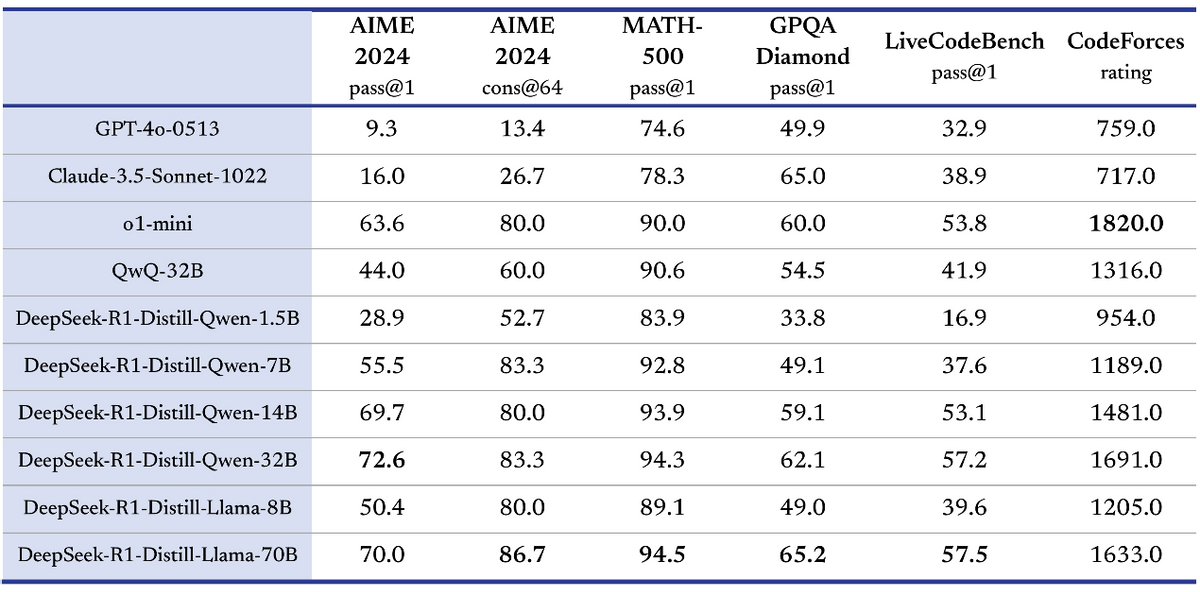
DeepSeek尚未公开R1的完整训练成本,但运行R1的费用仅为o1的约三十分之一。该公司还创建了6个R1的迷你“蒸馏”版本,以允许计算能力有限的研究人员使用该模型,其中32B和70B模型在多项能力上实现了对标OpenAI o1-mini的效果。
DeepSeek R1之所以引起业界的轰动,不仅仅是因为它实现了OpenAI O1大模型性能,且速度快5倍,价格便宜30倍;也不仅仅因为它彻底开源可商用;最重要的是,DeepSeek R1革新了自GPT以来,通用大模型训练的方式。
OpenAI定义了大模型训练的四个阶段:预训练、监督微调、奖励建模、强化学习。需要把海量的文本数据喂给模型,这就造成了大模型训练需要买卡建数据中心,通过堆算力喂数据解决问题。
DeepSeek则提出了一个全新的训练思路,直接强化学习这个路径,通过反复多次的强化学习,逼近最好结果。这种直接训练方法带来训练效率的提升,整个过程可以在更短的时间内完成。其次资源消耗降低,由于省去了监督微调和复杂的奖惩模型,计算资源的需求大幅减少。

众多AI业内人士通过社交媒体表达了震惊和欣喜。华尔街顶级风投A16Z创始人马克·安德森在社交媒体发言称,DeepSeek R1是其见过的最令人惊叹,最令人印象深刻的突破之一,并且是开源的,是给世界的礼物。英伟达资深科学家、AI智能体业务负责人Jim Fan也对其给予了高度评价。
纽约时报、英国金融时报、经济学人连线等海外媒体都对Deepseek进行了报道,并提出警告,中国低成本AI模型正威胁美国的领先地位。
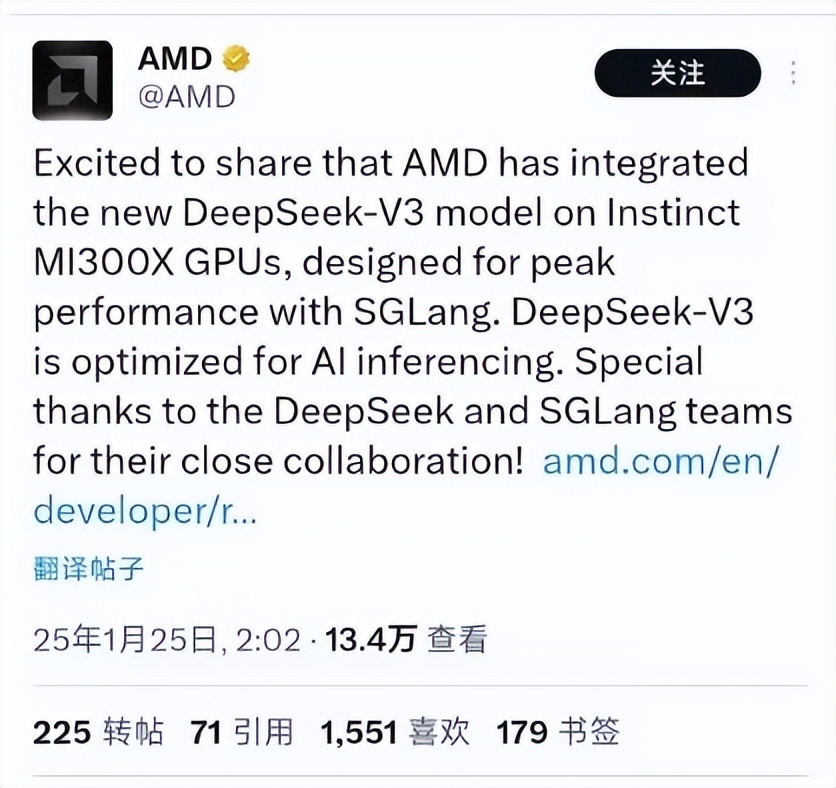
AMD则是宣布,已将新的DeepSeek-V3模型集成到Instinct MI300XGPU上,该模型旨在与SGLang一起实现最佳性能。DeepSeek-V3针对AI推理进行了优化。
1月24日,英伟达股价单日下跌3.12%,市值蒸发超300亿美元。目前还不清楚这波震荡是否与DeepSeek发布的开源模型R1有直接关系。
